
Introducing Portable OpenStreetMap outlined the components and basic workflow that POSM incorporates to facilitate the Missing Maps workflow in uncertain environments. This post will cover the philosophical and technical underpinnings of the POSM Replay Tool that allow it to participate as a contributing actor within the OSM ecosystem.
Why?
As designed, POSM packs a bag full of OpenStreetMap data and other stuff, heads to the beach, makes some edits, and heads back to work with a sunburn and a stack of changesets to show off as mementos. We want those edits to be submitted back to OpenStreetMap.org with less hassle than catching up on email.
How?
Ultimately, POSM branches OSM for a specific geographic area, facilitates offline edits while editing continues on OpenStreetMap.org, oblivious to field activity, and merges those offline edits back, resolving any conflicts that arose in the meantime.
Alas, it’s not quite that simple: OSM isn’t a true distributed system. Instead, POSM subverts the centralized revision control system nature of OSM and layers on distributed semantics in the same way that git-svn enables distributed workflows and Git semantics over Subversion.
Flowing data from a centralized system isn’t hard: you fork. There is a source of truth at the moment of forking. However, flowing data from the real world back into this centralized system is hard. As soon as data is added to the fork, “truth” becomes a relative construct. This is further compounded by the lack of internet connectivity and the inability to frequently reconcile. There are also inherent conflicts involving divergent content and different version numbers.
When internet connectivity is available and systems are regularly checking in with one another to compare and exchange modifications, we can take advantage of when edits were made to resolve differences and define “truth.” Without that, we need another way.
In Git terms, we’re applying changes from when we were offline to the “upstream” branch and then cherry-picking each local changeset onto it, minimizing the potential for and resolving merge conflicts as we go. Once we’ve ensured that changesets will apply cleanly, we submit each one to the OSM API and call it a day.
An OSM Digression
Before we continue, a brief digression into some of OSM’s traits that are relevant here. Depending on how you look at it, OSM is:
- an unconventional data model (nodes, ways, relations vs. OGC-style points, lines, polygons) that (largely) separates geometry from metadata while preserving topology
- a worldwide community of mappers (people with strong opinions and diverse backgrounds)
- an ODbL-licensed dataset (triggering attribution and share-alike requirements on commingled data)
- an ecosystem of tools (some with corporate-backing, many without)
- a financial opportunity
- a waste of time
- an “exchange database,” allowing organizations to collaborate with one another using OSM directly (simultaneously contributing to the commons)
- a single source of truth about features contained within it
- a centralized generator of element identifiers
In software engineering terms, OSM can be viewed as being / incorporating:
- a centralized revision control system (like CVS or Subversion)
- optimistic locking (using version numbers on elements), allowing conflicts to be identified quickly and avoiding the need to keep long-running transactions open
- log-structured storage (i.e. PostgreSQL database replication + minutely, etc. “diffs,” both of which track state using sequences)
- Subversion-like, in that it incorporates changesets (with associated commit messages and metadata) that group edits made to multiple elements (n.b.: changesets are not actually atomic)
- CVS-like, in that each element has a version associated with it (independent of all other elements)
Notably, OSM does not support delta updating of element properties, requiring the new state to be provided in full when properties are changed.
Particularly relevant to changeset replaying are OSM’s database and revision control traits. However, since OSM is neither obviously a database nor a revision control system, we need to carefully choose the traits upon which to layer the replay functionality. Some OSM functionality is atomic (or has ACID properties), but it’s difficult to recognize which and whether it’s appropriate to rely upon.
Unlike Osmosis’s implementation of replication using planet diffs, we don’t care about its “log-structured storage” trait, as the discrete units being replicated don’t map to publicly-available OSM data types (i.e. changesets) and are more intended for low-latency replication (measured in minutes, hours, or days).
We do care about its revision control trait, specifically the use of changesets to logically group edits (Subversion-style). In fact, we intend to treat those as atomic units (because they effectively are when editing is not occurring, even though they’re really not) when sourced from POSM.
Ok, Really, How?
POSM subverts the centralized revision control system nature of OSM and layers on distributed semantics in the same way that git-svn enables distributed workflows and Git semantics over Subversion.
OSM data and existing tools lend themselves well to creating derivatives — map data, analysis, or routes. Its architecture and ecosystem generally don’t facilitate merging data back in for two reasons. First, tracking the historical origin of nodes, ways and relations (“provenance”) is difficult (and often necessary!), but more importantly, OSM insists on minting all identifiers in use.
In a scenario where users create new elements in an OSM replica, we need to locally mint, track, and update identifiers. These elements cannot be submitted back to OSM.org directly, as OSM will almost certainly contain elements with the same IDs and entirely different content.
When merging involves submitting a single changeset, switching identifiers to placeholder values is straightforward (and exactly what happens when an editor saves). However, it gets incrementally more complex when multiple changes need to be applied, building upon one another.
The POSM Replay Tool is only a small part of a solution for managing disparate, linked datasets. It has no mechanism built-in to surface or resolve certain types of conflicts, specifically those where duplicate entities have been created independent of one another. This is the type of problem that QA tools should assist with, as it’s not inherently associated with a distributed workflow like POSM’s.
POSM is an eventually consistent component within the OSM ecosystem. It optimizes for availability (offline use) and partition tolerance (disconnected use) within the constraints of the CAP Theorem. Given that reconciliation can be done at an opportunistic time and the nature of edits is that there’s no natural ordering, serial numbers (in whatever form) can be ignored in favor of human resolution of minimally unresolved conflicts (minimized by considering delta updates locally).
OSM can also be seen as a distributed MVCC system where each instance of the database (or extract) presents a physically-isolated snapshot view of the database as a whole. In essence, the entire period POSM is disconnected from the internet can be considered as a single long-running MVCC transaction.
Reconciliation has a specific meaning in the context of eventually consistent systems. It is the “[process of] choosing an appropriate final state when concurrent updates have occurred.” (Wikipedia) Conflict resolution, in other words.
In a low-latency environment (like a database), this means choosing from multiple options according to some form of sequence (like a timestamp or a version number). However, since we’re dealing with human geography and long time-scales here, manual resolution (people!) is the most effective mechanism for judging which variant is most accurate.
To facilitate human intervention, we do the following during reconciliation:
- Reduce the diff size from an entity as a whole (i.e. all tags simultaneously) to properties of that entity (individual tags), allowing us to consider delta updates locally, reducing the surface area of potential conflicts
- Invoke an interactive handler for conflicts that cannot be resolved automatically (currently a textual diff, but this should become visual in the future)
Because we’re attempting to reduce the problem of merging data to something human-scale, we care deeply about intentionality. Changesets are OSM’s mechanism for bundling up edits into groups of described intention. We treat them as fundamental to the way POSM replaying works and as the underlying units of work to be synchronized. One reason we can get away with this is that changes (locally) aren’t happening in real-time — we can pick our moment to synchronize.
Using changesets is only a small part of the approach, but arguably one of the key insight that makes the problem tractable. Osmosis and associated tools are intended to replicate (in one direction) changes as they happen, ignoring intentionality and subjective grouping. This forced us to go our own way.
OSM Changesets, Briefly
From the name, you’d expect that changesets are atomic, but they’re not. After you open a changeset, you have 24 hours to fill it with actual changes (each sub-change is atomic and can be rejected if the optimistic locking fails) before it’s closed.
As a result, changesets are really more about grouping sets of individually atomic edits. This is fine for our purposes.
So, How Does It Actually Work?
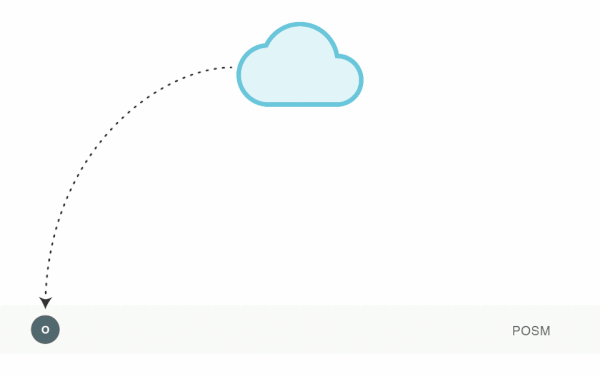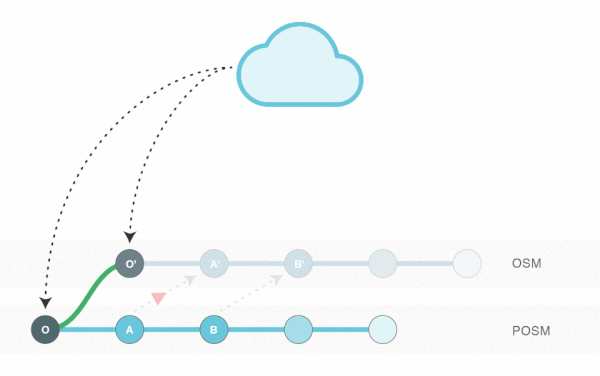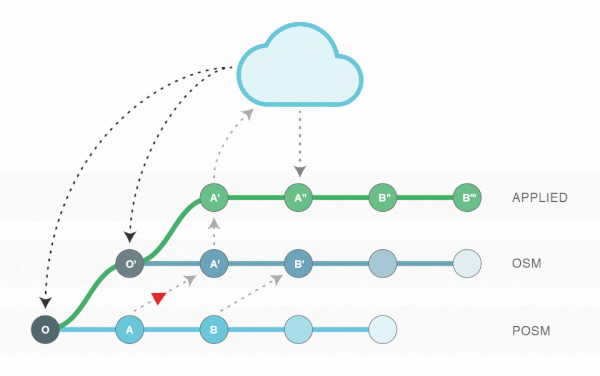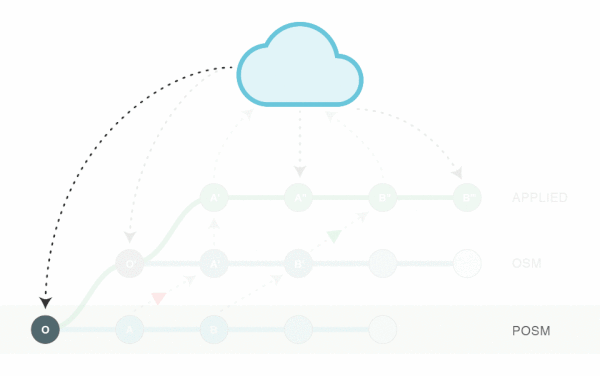
Given all of the above, the POSM Replay Tool’s solution is to create a local Git repository containing the current state (local edits), transform it so that it contains the new desired upstream state (what OSM should look like after merging), and apply the necessary transformations (in the form of API calls) to update the upstream state.
XML representations of OSM elements (nodes, ways, relations, and changesets) are converted into YAML, a line-based, diff-friendly format, in order to take greater benefit of the change tracking mechanisms Git provides.
The overall process looks approximately like this:
- Gather local changesets
- Establish a branch point using the extract used to initialize POSM, filtering the elements tracked to those touched by local changesets (reducing the number of elements being tracked)
- Apply local changesets to the previously established branch point
- Apply the current upstream state (using an updated extract of the same area) to the branch point
- Rebase all local changesets against the upstream branch to produce the new desired state
- Resolve conflicts manually, if encountered
- Submit each commit as a changeset to the upstream API (OpenStreetMap.org)
- Create a pair of commits for each commit, one for the changeset as submitted, one for transformations (element renumbering) resulting from the DiffResult response
Preparation
Changesets are fetched from the local API, starting from the first update made to POSM and continuing until all have been downloaded.
A list of unique elements modified within these changesets and used to filter the OSM extract that was used to initialize POSM (and which was put aside for this purpose).
Filtered elements are converted to YAML and committed to a new Git repository created to facilitate replaying of local edits.
Each changeset is applied as an individual commit, tracking its metadata as a Git commit message. Changeset contents are transformed into diffs applied to each referenced element.
Since OSM is also an “unconventional” data format that (partially) separates metadata from geometry (nodes are the only element type that have an implicit geometry), tracking them independently in the repository (element per file) reduces the surface area for conflicts by increasing granularity.
This is what a node looks like as YAML:
$ cat nodes/1356792705.yaml
lat: -3.4957935
lon: -80.2089977
uid: 2652419
user: anjikoc
Properties like “version” and “user_id” have been omitted, as they don’t provide useful context and can introduce unnecessary conflicts.
A way:
$ cat ways/415138093.yaml
nds:
- 4162062295
- 4162062297
- 4162062300
- 4162062298
- 4162062295
tags:
building: residential
condition: poor
level: ‘1’
material: concrete
street: Atahualpa
uid: 3655743
user: POSM
Nodes are represented as a list (relations handle members in the same way). This allows the shape of a way to be modified without triggering a conflict on the underlying metadata (by moving referenced nodes). Nodes can be added to or removed from the list to manipulate the geometry; these will only trigger conflicts if adjacent nodes are simultaneously modified.
YAML is line-based, so dealing with merge conflicts can be done in a relatively straightforward manner using existing text manipulation tools, e.g. those invoked by git mergetool. For the purposes of development, I used Xcode’s FileMerge tool (which isn’t even a 3-way merge tool; it turned out that that wasn’t a useful feature here).
We take the current upstream state (for the same extract area; actually, for the same set of elements that were modified, matching those that were already being tracked) and apply it on top of the previous upstream state as a new commit.
Now that we have the “new upstream,” we can cherry-pick (in git terms) each of the commits from the POSM branch and apply them to it, resolving merge conflicts as we go. This is equivalent to running git svn rebase against a Subversion repository.
(Triangles represent conflicts. They’re red when intervention is required, green when they’re flagged but can be resolved automatically; you’ll see one shortly.)
Apply Changes to an Upstream API
Once all of the commits have been cherry-picked and rebased against the new upstream, we can create a new branch called APPLIED and automatically cherry-pick each resolved commit and submit it to the upstream OSM API.
After each commit has been cherry-picked onto the applied branch, it is converted to an OSMChange file and uploaded to a new changeset. The response from OSM is a DiffResult, which contains a mapping of submitted IDs to newly-minted IDs. (Because we’re able to determine which IDs were minted by POSM, we map those to negative numbers before submission to avoid inadvertent references to unexpected elements.)
Sample DiffResult:
<?xml version=”1.0" encoding=”UTF-8"?>
<diffResult version=”0.6" generator=”OpenStreetMap server” copyright=”OpenStreetMap and contributors” attribution=”http://www.openstreetmap.org/copyright" license=”http://opendatacommons.org/licenses/odbl/1-0/">
<node old_id=”-1" new_id=”4162080889" new_version=”1"/>
<way old_id=”-2" new_id=”415139941" new_version=”1"/>
<node old_id=”3907104764" new_id=”3907104764" new_version=”2"/>
</diffResult>
Using the DiffResult, we can renumber (rename) each of the elements that were assigned new IDs by the upstream API. We can also go through each way and relation tracked in the Git repository to find references to elements with updated IDs and change them. Renumbering is an additive process (subsequent commits should be renumbered according to all previous DiffResults), so information about which elements were renumbered (including their original and target identifiers) is included as metadata within the repository.
The diff produced by the renumbering process is turned back into a commit (with the DiffResult as the commit message) within our local Git repository to facilitate tracking, debugging and to provide a record of what was performed.
Aʺ is the result of renumbering with the DiffResult as the commit message:
We keep doing this until we’ve applied all of the local changesets:
if (when, really) we run into merge conflicts when cherry-picking onto the APPLIED branch (due to elements that have been renumbered), we can automatically reconcile them, as the conflicts were already resolved when preparing the OSM branch. Ignoring version numbers helps prevent conflicts from being raised by the upstream API; current element versions are looked up when generating an OSMChange file from a Git commit.
The optimistic locking nature of OSM means that version numbers have correct values in 2 contexts: before they’re submitted (referencing the version to be updated) and after they’ve been accepted (the new version). POSM incorporates an instance of the OSM API, so local revisions also have their own versions, which are incremented each time an element is edited. When submitting upstream, each of those edits results in the remote version being incremented. It’s possible to track them properly, but it’s not necessarily worthwhile given the confusion introduced and the fact that intermediate element history is tracked during the intermediate process.
This part of the workflow is equivalent to “git svn dcommit”, where Git commits are checked in as Subversion revisions and updated with metadata about the revision number that they were assigned.
Wrap Up
The Git repository we produced includes all of the history and context used for reconciliation. Once synchronization has been completed, its primary purpose is as an artifact of the merge process. Rather than partially applying upstream changes to POSM’s database, it’s much easier to replace all of the data with a new extract.
The above describes the process as it occurs in theory. In reality, we’ve used this to contribute edits made by about 30 Cruz Roja Ecuatoriana volunteers this spring (~15,000 elements touched across ~350 changesets). Because we have no real way to propagate the identity of those volunteers (device / person / internet need to be simultaneously present for authorization), we treat submission as a sort of import and tie all changesets to an OSM user created specifically for the merge.
Why Git?
- The existence of git-svn and git-cvs and associated documentation
- Diff- (delta-)based, merge conflict friendly
- Distributed / multi-master, designed for disconnected work
- Git objects are immutable
- Considers changes to the data as a whole (vs. individual entities) when forming commits
- Git’s underlying representation is a Directed Acyclic Graph (with merges supported), lending itself to reasoning about changes as state transitions, especially when elements are represented as individual files
- Git primitives / plumbing / porcelain make it suitable for unconventional (ab)use at a granular level
Future Directions
- Upstreams other than OpenStreetMap.org (OSM-style APIs hosting non-OSM data)
- Proper tracking of versions so that OSM’s optimistic locking can work as intended (eliminating the brief window (measured in seconds-to-minutes) where conflicts are blindly resolved by ignoring upstream changes which would have otherwise been taken into account outside the window) — in practice this isn’t a problem yet, as areas taken offline typically experience minimal online editing behavior
- Propagation of editor identities using changeset tags (can’t be verified, but will facilitate attribution)
- Visual conflict resolution, pulling additional context from the local and upstream APIs to show geometry changes (although this will require deeper plumbing due to externally referenced elements needing to be looked up by time rather than naïvely using current versions)
- Generation of GeoJSON representations of elements (reconstructing geometries) to facilitate retroactive exploration of changes using GitHub’s visual map differencing functionality
I’d like to thank Greg, Jay, Nick, the Stamen crew, the Red Cross folks, and various others whose ear I’ve bent for their help in making this as clear as it is.