
New Tools for Research with UC Berkeley
Explore, Compare, Inspire!
Most people know that the University of California at Berkeley is a world-class research university. Some folks have heard of the Hearst Museum of Anthropology. But not so many people know that the university houses seven natural history museums which together hold 12 million specimens that form the most complete representation of our state’s living and extinct plants and animals. Our new work with Cal is designed to help change that. The Ecoengine is a powerful resource for understanding changing ecosystems, more than ever a crucial challenge for our times.
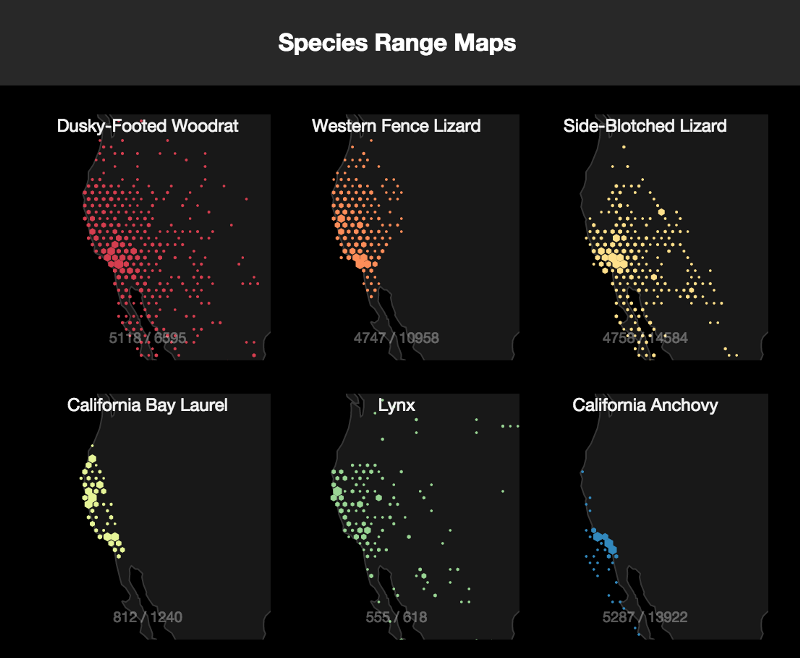
We’re thrilled to have built the main interfaces for searching and analyzing that data about those specimens, along with a whole lot more information that’s been brought together in a single database and API called the Berkeley Ecoinformatics Engine (also known as the Ecoengine).
The Ecoengine API is already a remarkable resource for the most tech-savvy academics. Our job was to make it searchable by researchers and students who would rather use a web browser to discover data and test hypotheses than jump straight into the statistics package R or proprietary desktop GIS systems.
The challenge, then, was to create interfaces that hide none of the complexity of the data — researchers want to see it all, no dumbing down! — but also that are intuitive to use and that produce findings that are easy to share.
The Ecoengine has data from specimens collected around the world, though the collections are concentrated in California.
Explore
With millions of data points across thousands of categories, Explore presented a challenge of designing a search interface that’s highly flexible, but also gets results quickly and is easy to learn.
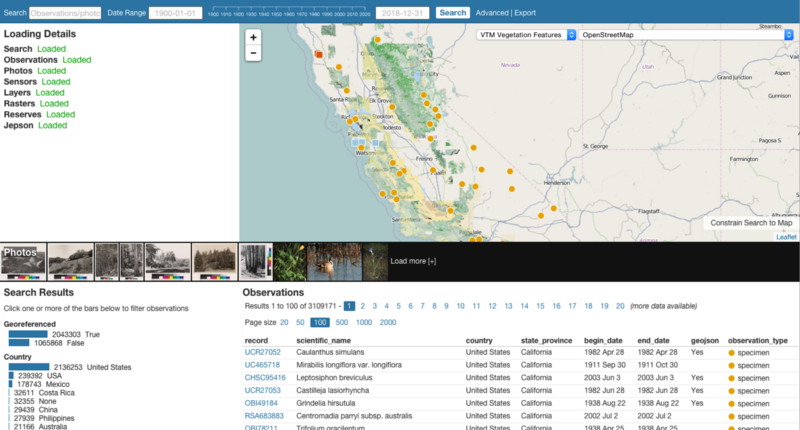

The facets along the left side, which are a key part of the underlying database, also give an immediate sense of the scope of the Ecoengine data and allow you to quickly drill into the data even if you’re not sure what to search for at the outset. In the screenshot above, in just a few clicks, we narrowed the scope down to just birds in California with known locations and physical specimens in the collection.
At right, the default facets immediately tell you the scope of the available data: mostly in the United States, mostly in California, and predominantly animals.
The search box at the top allows for very specific queries (like for a species name) and the timeline next to it lets you narrow your search to a slice of a few years.
Compare
After we developed Explore, Charles Marshall (director of the Museum of Paleontology and one of the principal investigator on the Holos/Ecoengine project) challenged us to push further in our second phase.
A common limitation of web-based biodiversity databases is that you’re limited to seeing one query at a time. Our charge from Charles was to “break the lock of single-taxa views of change.”
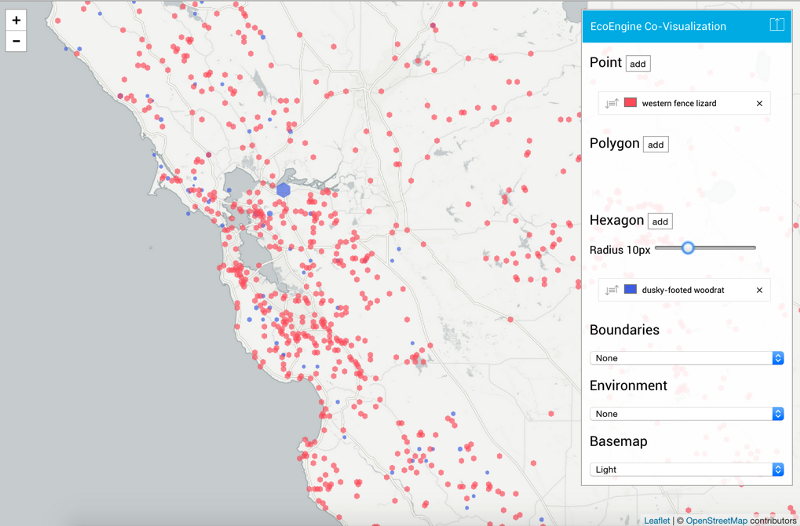
So we designed an interface purpose-built for comparing diverse spatial datasets. It starts with either simple term queries of the Ecoengine entered directly in the Compare tool, or with more complex queries brought over from the Explore tool. These can include facet selections, time ranges and bounding box filters as well as search terms.
Here’s an example comparing observations of western fence lizards and dusky-footed woodrats:
That might seem like an obscure thing to search for! But by different indirect mechanisms, fence lizards help keep Lyme disease occurrence low. Woodrats increase occurrence. So this is a map with some direct interest for anyone concerned about Lyme disease.
The interface is highly configurable, with drag-and-drop layers, custom labels, editable colors, and multiple basemap options. It includes boundaries (like state, county, ecoregion), our own Terrain layer, and the light and dark maps we designed for CartoDB:
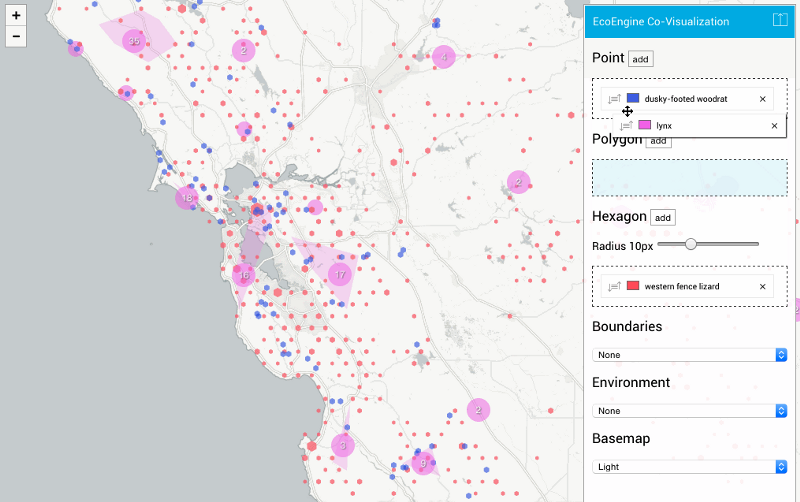
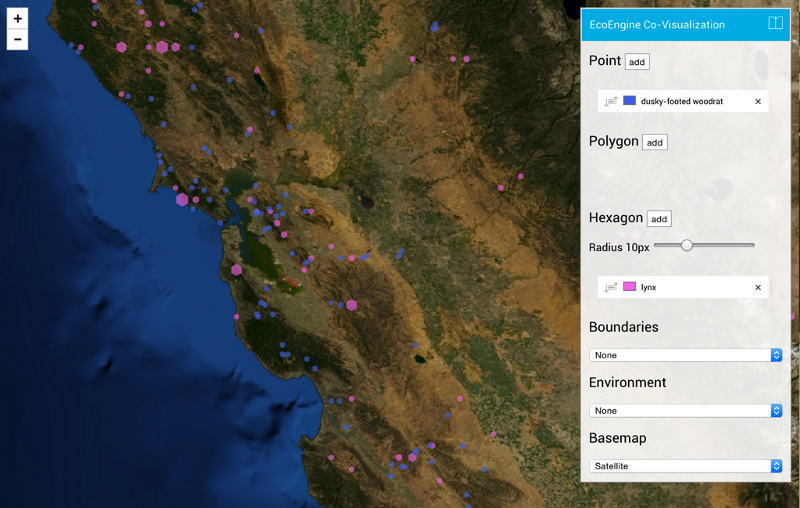
And every map configuration can be easily bookmarked and shared, since we write the queries and configurations into the stateful URL.
Inspire
The Explore and Compare interfaces needed to look at home on the holos.berkeley.edu website (and work within a larger production environment). Just as important, our work needed to lay the foundation for other developers to use the freely available API to build their own tools for use cases none of us at Stamen or at the University had previously considered.
Making code open source is one thing (and we’ve done a lot of that). Making it easy to understand and reuse is another. and that’s even harder if the code then needs to work within a production CMS (in this case, Mezzanine).
The solution here came about rather naturally: divide the load. So we have two production interfaces that can be built and deployed on the main Holos site, and then we have other versions and prototypes of many more interfaces that are right at home on Github Pages:
Steal this code!
The Explore and Compare interfaces also run just fine on Github Pages (see Explore and Compare). So fork and modify! But those are pretty complex, and we made many other prototypes along the way. We hope the examples below will inspire others to grab the code and try their hands at making their own ecovisualizations.
Antarctic Chordata
- A stress-test of loading all Chordata in a non-Mercator projection centered on Antarctica
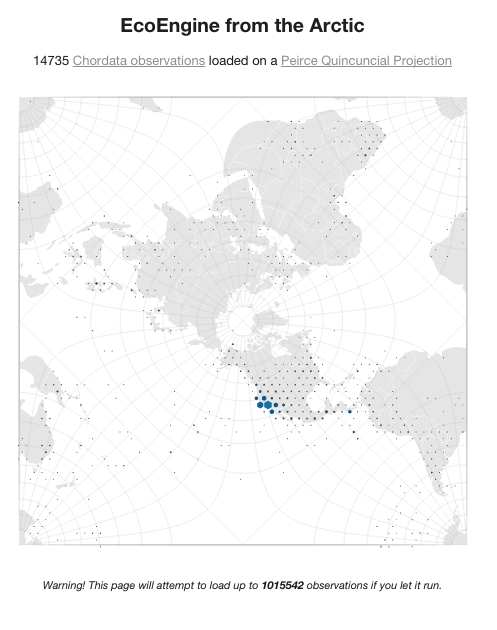
Arctic Chordata
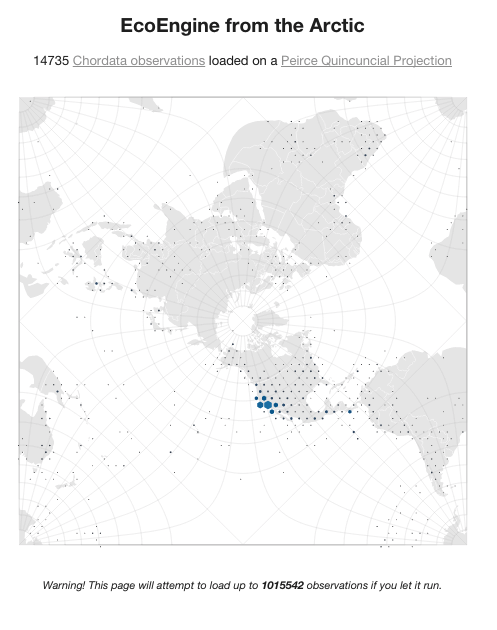
- The same as the previous, but centered on the North Pole
Lizards and Woodrats
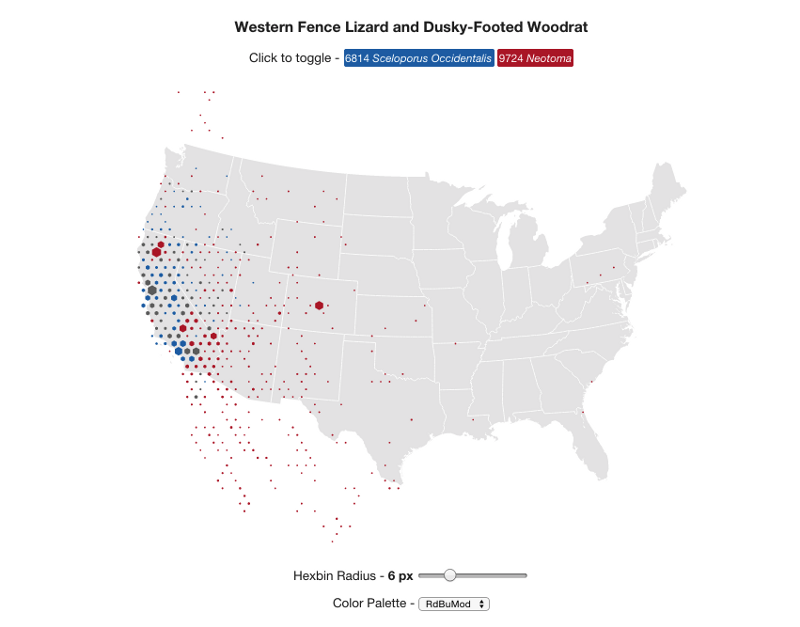
- Spot spatially co-occurring observations by toggling layers
Taxa Sampling Distributions
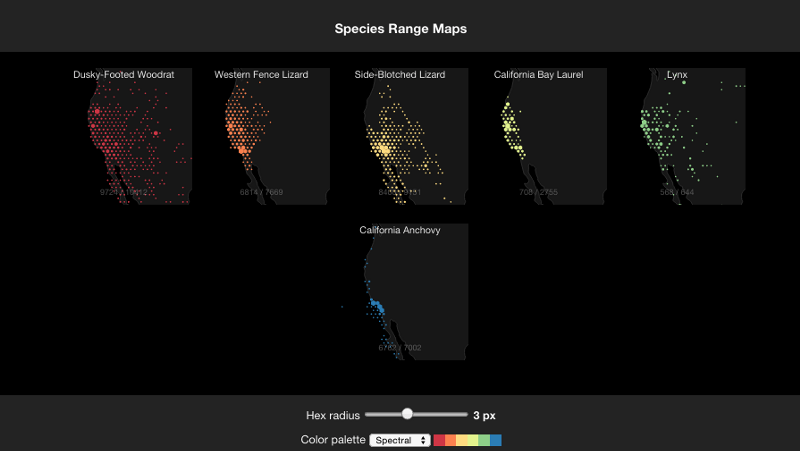
- Example of small multiples to compare sampling distributions.
- ColorBrewer palettes
Woodrats over Decades
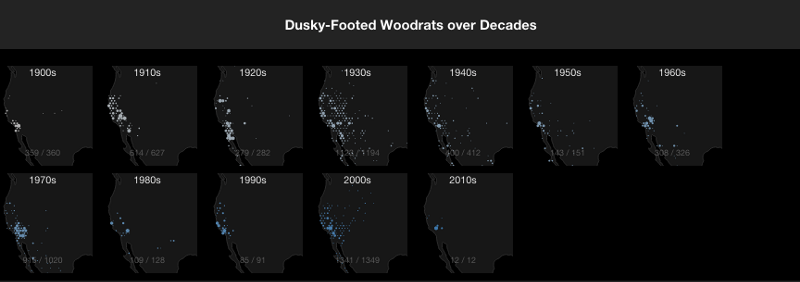
- Example of small multiples to compare temporal distributions
Quercus
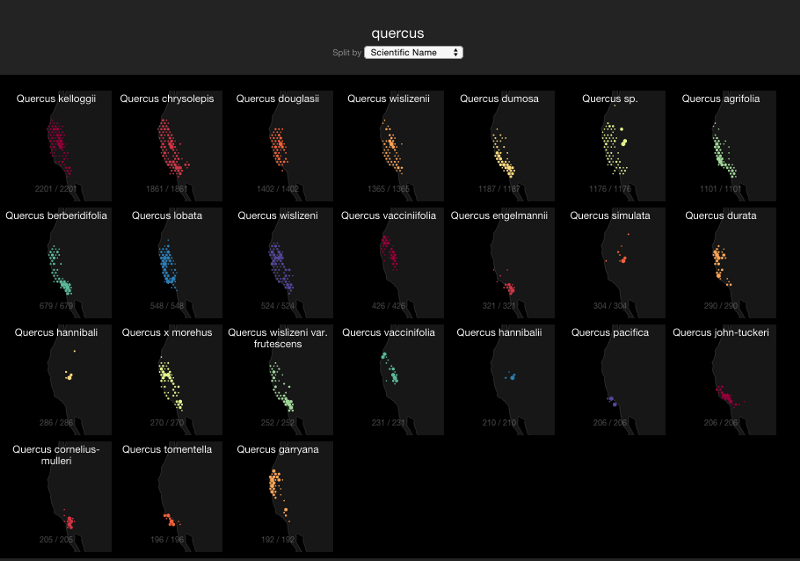
- Small multiples with search functionality (edit “quercus”)
- Split by search facet
- Displays top 24 facets for a search
Photos

- Simple photo-viewing app, accepts URLs in the same format as Explore
Bulk Download
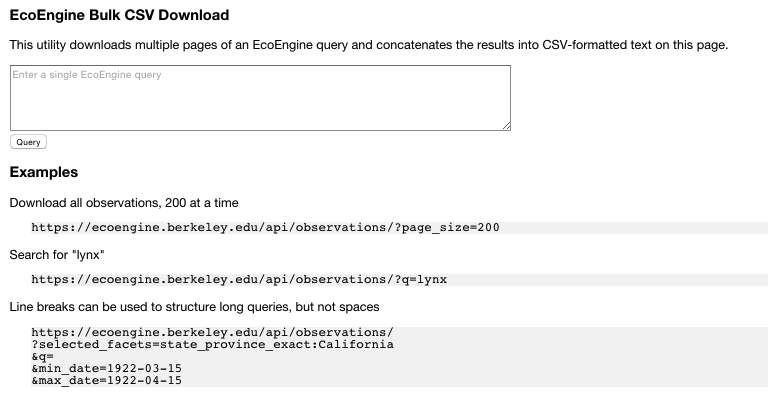
- A tool for generating CSV text from a query
- Downloads multiple pages of data. A limitation of the API is that results are always paginated, so loading all data for a query requires some work.
Observations
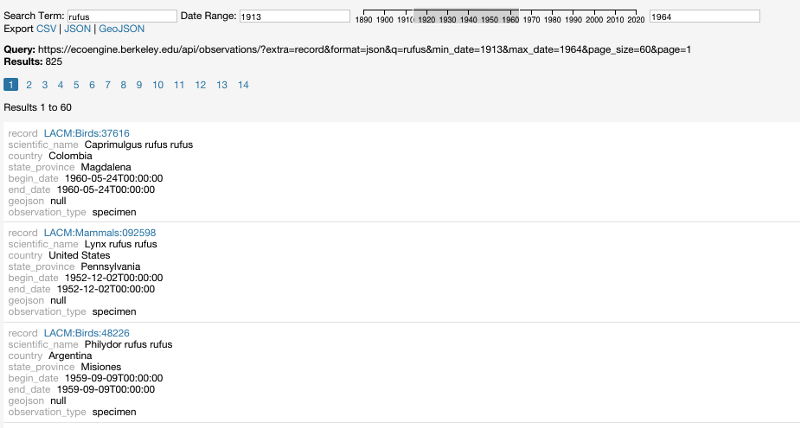
- An early version of Explore with search box, time filter, pagination and export options
- Could be a good starting place for new EcoEngine applications, since the app is only about 250 lines long and uses only d3.js
Early version of Explore
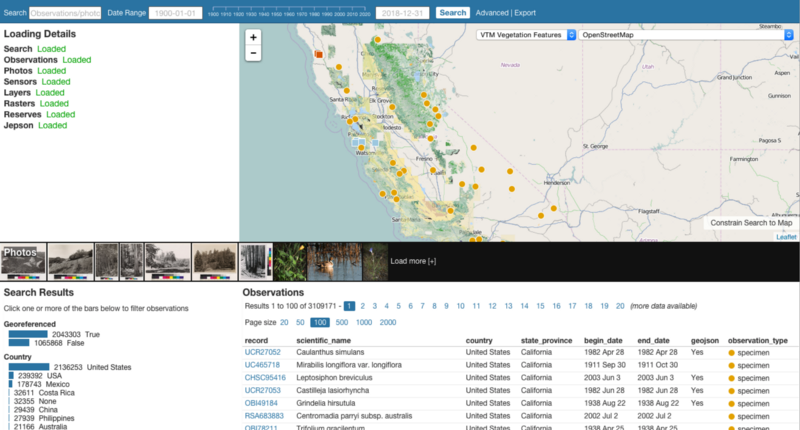
- An early version of explore with a preview of available photos and a “Detail” pane that lists out information about observations that are hovered over.
Sensors

- A simple “hello world” of accessing and printing EcoEngine data with d3
- Lists an index of available sensors
Scatterplot
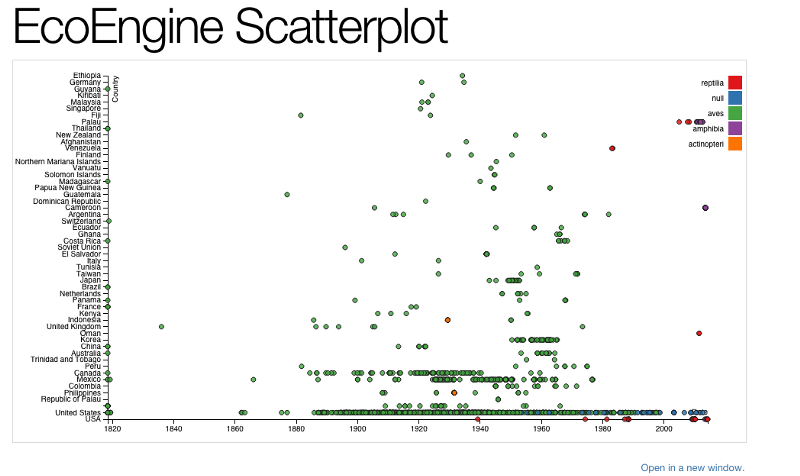
- A simple D3.js scatterplot showing observations by country over time.
Parallel Coordinates
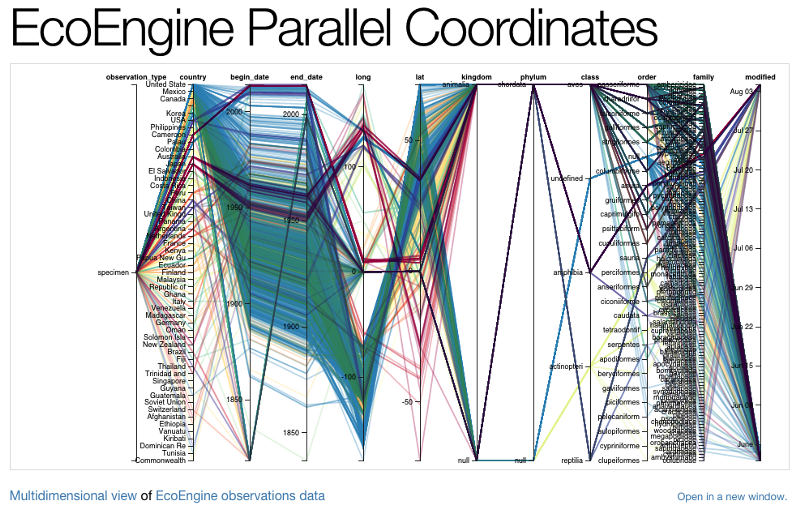
- A D3.js parallel coordinates plot showing a sample of 2000 observations.
The Berkeley Ecoinformatics Engine is funded by the W. M. Keck Foundation.